美團(tuán)大數(shù)據(jù)查詢與數(shù)據(jù)處理技術(shù)體系 架構(gòu)、核心與演進(jìn)
在當(dāng)今數(shù)據(jù)驅(qū)動(dòng)的商業(yè)時(shí)代,美團(tuán)作為連接數(shù)億消費(fèi)者與數(shù)百萬(wàn)商家的本地生活服務(wù)平臺(tái),其背后高效、可靠的大數(shù)據(jù)查詢與數(shù)據(jù)處理技術(shù)體系是支撐其業(yè)務(wù)決策、用戶體驗(yàn)優(yōu)化和智能運(yùn)營(yíng)的基石。這一技術(shù)體系不僅需要應(yīng)對(duì)海量、多源、實(shí)時(shí)的數(shù)據(jù)挑戰(zhàn),更需滿足從即時(shí)交互查詢到復(fù)雜離線分析的多元化需求,其技術(shù)開(kāi)發(fā)與實(shí)踐代表了行業(yè)的前沿水平。
一、 整體架構(gòu):分層解耦與流批一體
美團(tuán)的大數(shù)據(jù)技術(shù)架構(gòu)通常遵循分層設(shè)計(jì)理念,以實(shí)現(xiàn)模塊解耦與靈活擴(kuò)展:
- 數(shù)據(jù)采集層:通過(guò)自研或集成的工具(如DataX、Flume、Kafka Connector),從APP、服務(wù)器日志、數(shù)據(jù)庫(kù)Binlog、第三方API等源頭,進(jìn)行實(shí)時(shí)與離線的數(shù)據(jù)采集與同步,形成原始數(shù)據(jù)湖。
- 存儲(chǔ)計(jì)算層:這是核心引擎層。美團(tuán)深度應(yīng)用并優(yōu)化了以Hadoop(HDFS)、Hive、Spark、Flink、Presto/Trino為核心的開(kāi)源生態(tài),并自研了相關(guān)組件。例如,通過(guò)Hive/Spark進(jìn)行大規(guī)模的批量ETL(抽取、轉(zhuǎn)換、加載)處理;通過(guò)Flink構(gòu)建強(qiáng)大的實(shí)時(shí)計(jì)算能力,支持毫秒級(jí)到秒級(jí)的流數(shù)據(jù)處理;通過(guò)Presto/Trino提供高效的交互式即席查詢(Ad-hoc Query)。
- 查詢服務(wù)與治理層:在統(tǒng)一計(jì)算引擎之上,構(gòu)建了數(shù)據(jù)服務(wù)網(wǎng)關(guān)、統(tǒng)一元數(shù)據(jù)管理、數(shù)據(jù)血緣追蹤、數(shù)據(jù)質(zhì)量監(jiān)控與成本治理平臺(tái)。這一層使得數(shù)據(jù)的發(fā)現(xiàn)、理解、使用和管控更加便捷與規(guī)范,是提升數(shù)據(jù)資產(chǎn)價(jià)值與可靠性的關(guān)鍵。
- 應(yīng)用層:直接面向業(yè)務(wù),包括實(shí)時(shí)監(jiān)控大屏、AB實(shí)驗(yàn)平臺(tái)、用戶畫像系統(tǒng)、推薦與搜索算法模型、經(jīng)營(yíng)分析報(bào)表等,這些應(yīng)用直接依賴于底層高效的數(shù)據(jù)處理與查詢能力。
二、 核心查詢技術(shù):速度、規(guī)模與易用性的平衡
針對(duì)不同的查詢場(chǎng)景,美團(tuán)采用了多樣化的技術(shù)方案:
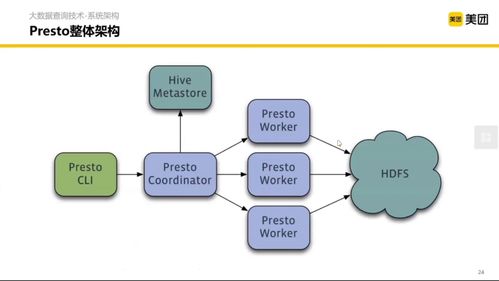
- 交互式即席查詢:Presto/Trino 是核心引擎。美團(tuán)團(tuán)隊(duì)對(duì)其進(jìn)行了大量深度優(yōu)化,包括但不限于:定制化的連接器(Connector)以更好適配內(nèi)部存儲(chǔ)格式;優(yōu)化查詢計(jì)劃與執(zhí)行引擎,針對(duì)復(fù)雜Join和大表聚合進(jìn)行性能調(diào)優(yōu);增強(qiáng)多租戶資源隔離與管理能力,保障查詢穩(wěn)定性。這使得數(shù)據(jù)分析師和工程師能夠以“秒級(jí)”速度探索PB級(jí)數(shù)據(jù)。
- 在線數(shù)據(jù)服務(wù)查詢:對(duì)于需要低延遲(毫秒級(jí))響應(yīng)的在線業(yè)務(wù)查詢,如訂單詳情、商戶信息實(shí)時(shí)聚合等,美團(tuán)構(gòu)建了基于Apache Doris(或類似MPP數(shù)據(jù)庫(kù))和Redis等系統(tǒng)的實(shí)時(shí)數(shù)倉(cāng)與緩存體系。Doris兼具高并發(fā)點(diǎn)查和批量分析能力,能夠很好地支撐實(shí)時(shí)報(bào)表和在線數(shù)據(jù)服務(wù)接口(Data API)。
- 圖數(shù)據(jù)查詢:在社交關(guān)系、風(fēng)控網(wǎng)絡(luò)、地理位置推薦等場(chǎng)景,美團(tuán)研發(fā)并應(yīng)用了圖計(jì)算與圖查詢技術(shù)(如基于Spark GraphX或自研圖引擎),以高效處理實(shí)體間的復(fù)雜關(guān)聯(lián)關(guān)系查詢。
三、 數(shù)據(jù)處理技術(shù):從批量ETL到實(shí)時(shí)數(shù)倉(cāng)
數(shù)據(jù)處理管道是數(shù)據(jù)價(jià)值提煉的流水線,其技術(shù)演進(jìn)體現(xiàn)了從“T+1”到“實(shí)時(shí)化”的進(jìn)程:
- 批量處理:基于 Apache Spark 和 Hive 的ETL作業(yè)仍然是處理歷史數(shù)據(jù)、構(gòu)建主題數(shù)據(jù)倉(cāng)庫(kù)(DW)和數(shù)據(jù)集市(DM)的主力。美團(tuán)通過(guò)作業(yè)調(diào)度系統(tǒng)(如Airflow或自研調(diào)度平臺(tái))管理復(fù)雜的依賴關(guān)系,并利用Spark的內(nèi)存計(jì)算優(yōu)勢(shì)大幅提升處理性能。
- 實(shí)時(shí)流處理:Apache Flink 是實(shí)時(shí)數(shù)據(jù)處理的基石。美團(tuán)利用Flink構(gòu)建了端到端的實(shí)時(shí)數(shù)據(jù)管道,實(shí)現(xiàn):
- 實(shí)時(shí)ETL:對(duì)Kafka中的流數(shù)據(jù)進(jìn)行清洗、轉(zhuǎn)換、打?qū)挘?shí)時(shí)寫入OLAP引擎(如Doris)或消息隊(duì)列供下游消費(fèi)。
- 實(shí)時(shí)聚合:進(jìn)行窗口計(jì)算(如每分鐘交易額、每小時(shí)UV),支撐實(shí)時(shí)業(yè)務(wù)監(jiān)控與決策。
- 事件驅(qū)動(dòng)應(yīng)用:如實(shí)時(shí)風(fēng)控、動(dòng)態(tài)定價(jià)、智能調(diào)度等,對(duì)數(shù)據(jù)流的處理延遲要求極高。
- 流批一體與數(shù)據(jù)湖倉(cāng):為統(tǒng)一實(shí)時(shí)與離線的開(kāi)發(fā)體驗(yàn)與數(shù)據(jù)口徑,美團(tuán)正積極向 “流批一體” 架構(gòu)演進(jìn)。通過(guò)將Flink的流處理能力與Hive/Iceberg等數(shù)據(jù)湖表格式相結(jié)合,實(shí)現(xiàn)一套代碼同時(shí)處理實(shí)時(shí)流和歷史批數(shù)據(jù),數(shù)據(jù)在湖中統(tǒng)一存儲(chǔ),并通過(guò)統(tǒng)一的SQL服務(wù)進(jìn)行查詢,這極大地簡(jiǎn)化了架構(gòu)復(fù)雜度并保證了數(shù)據(jù)一致性。
四、 技術(shù)開(kāi)發(fā)的關(guān)鍵方向與挑戰(zhàn)
美團(tuán)大數(shù)據(jù)技術(shù)的持續(xù)開(kāi)發(fā)聚焦于以下幾個(gè)關(guān)鍵領(lǐng)域:
- 性能與成本優(yōu)化:在數(shù)據(jù)量持續(xù)增長(zhǎng)的背景下,通過(guò)數(shù)據(jù)壓縮、智能分層存儲(chǔ)(熱/溫/冷)、計(jì)算資源彈性調(diào)度、作業(yè)智能調(diào)優(yōu)等手段,持續(xù)降低存儲(chǔ)與計(jì)算成本,提升資源利用率。
- 穩(wěn)定性與SLA保障:構(gòu)建全鏈路的數(shù)據(jù)質(zhì)量監(jiān)控、故障自愈與血緣分析能力,確保關(guān)鍵數(shù)據(jù)管道和查詢服務(wù)的可用性達(dá)到99.99%以上,快速定位與修復(fù)數(shù)據(jù)問(wèn)題。
- 智能化與自動(dòng)化:利用AI技術(shù)實(shí)現(xiàn)數(shù)據(jù)治理的智能化,如自動(dòng)標(biāo)注數(shù)據(jù)、智能推薦關(guān)聯(lián)數(shù)據(jù)集、自動(dòng)檢測(cè)數(shù)據(jù)異常與根因分析。
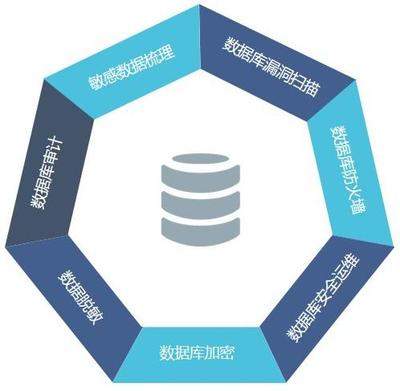
- 安全與合規(guī):加強(qiáng)數(shù)據(jù)全生命周期的安全管控,包括敏感數(shù)據(jù)識(shí)別與脫敏、細(xì)粒度的權(quán)限訪問(wèn)控制(基于RBAC或ABAC模型),以滿足日益嚴(yán)格的數(shù)據(jù)安全法規(guī)要求。
###
美團(tuán)的大數(shù)據(jù)查詢與數(shù)據(jù)處理技術(shù)體系是一個(gè)持續(xù)進(jìn)化、緊密貼合業(yè)務(wù)的復(fù)雜有機(jī)體。它并非單一技術(shù)的堆砌,而是對(duì)Hadoop/Spark/Flink/Presto等開(kāi)源生態(tài)的深度內(nèi)化、定制優(yōu)化與創(chuàng)新集成。其核心目標(biāo)始終是:以更低的成本、更快的速度、更高的可靠性,將數(shù)據(jù)轉(zhuǎn)化為可行動(dòng)的洞察,賦能每一個(gè)業(yè)務(wù)場(chǎng)景的精細(xì)化運(yùn)營(yíng)與創(chuàng)新。 隨著實(shí)時(shí)化、智能化和一體化的趨勢(shì)加深,這一技術(shù)體系將繼續(xù)引領(lǐng)本地生活服務(wù)領(lǐng)域的數(shù)據(jù)驅(qū)動(dòng)實(shí)踐。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://m.mcwl668.cn/product/74.html
更新時(shí)間:2026-05-13 13:28:55